Voice Identity Experience Design
语音形象体验设计
2016-2018
Alibaba Cloud & KTH
作为虚拟语音助理,Siri和Cortana都以成熟的VUI形成了自己的品牌。YunOS中的小云作为后来者,不仅承载了万物互联的品牌属性,也且希望提供亲切灵动的语音可视化形象和更加友好的语音交互界面。在此基础上,我进一步进行设计延伸,设计更加具有视觉动态特征的语音形象和交互。本项目不涉及公司产品设计,仅为个人设计思路拓展习作。
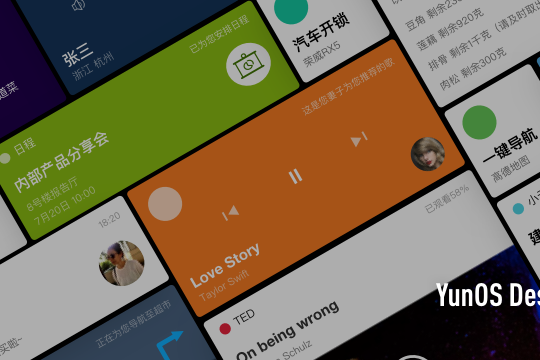
01 系统语音助理小云形象设计
Visual Identity Design for Voice Assistant
为了追求达到局部和整体的统一,也达到静态和动态的平衡,我参考分形学的诸多理论,尝试设计一个动态但又平衡的小云结构。与其它手机系统语音形象不同的是,我没有尝试一个简单的几何形表达,而是希望通过有序的结构表达简单和高效的语音反馈表现。灵感来自于国外研究“Shape of Sound”。

为了在屏幕内更好的展示差异化的语音形象,并且能让微小的视觉语音反馈都能被用户感知,我设计了不完全形状来最大化视觉效益和形象的交互性。
小云的变化模式机制为:颜色与状态有关,变化速度、幅度和形状和用户声音性质有关

小云可以在交互中作为场景服务整合的载体,让语音形象真正成为个人助手


将图形至于屏幕下方,让整个语音交互体验的视觉表达更自然和协调

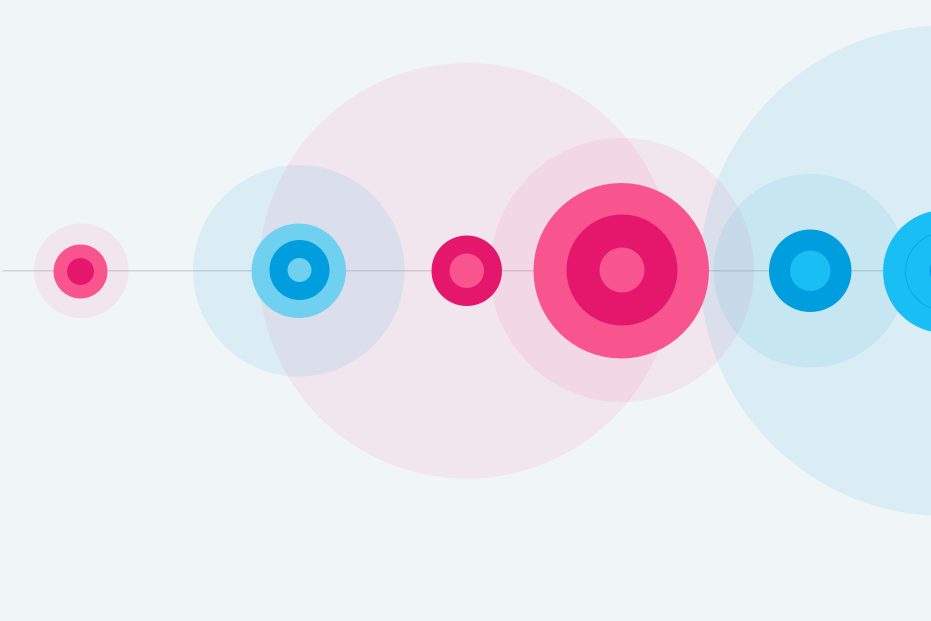
02 一个实时声音可视化设计
Real-time Sound Visualization Design
得益于小云进行可视化声音反馈的灵感,我开始有了利用视觉来记录声音的灵感。一个环境声音实时记录系统,用户能通过对可视化图形的识别,回忆起这是什么声音,发生在什么时候,从而勾起用户故事记忆。
真实录制视频点击 <声音可视化VisRecord>
声音的各种特征根据通过傅立叶变换进行量化,然后影响可视化图形中各个部件的颜色、尺寸、粗细、透明度…

边缘花形的设计利用了人眼只能分辨有限帧数的特性,让椭圆在不同帧内的运动轨迹来构成看似“静态的花朵状”。而运动的熟悉由声音的各种频率决定。时间轴会通过每个瞬间声音的性质绘制并连在一起


每个瞬间,都完全由不同的声音性质组成