Visualization for Academic Hiring
为学术招聘进行数据可视化工具设计
2019
INRIA, Aviz
在科研机构招聘新的研究人员时,通常会设立招聘委员会,成员是来自机构内不同的研究方向的科学家。招聘委员会成员通常会在审阅和评估申请材料时遇到很多问题:比如需要查看大量的文字的非结构化信息,通过这些复杂的信息比较不同的申请者,在不一致的观点中确定最终排名。我的目标是去研究是否可以通过可视化的手段来缓解这些问题,在提高科研招聘质量的同时也优化流程中的用户体验。我在法国国家信息研究院(Inria)的Aviz团队进行这个项目的设计和研究。
01 研究和设计方法
Methodology

02 文献研究&相关产品
Literature Research
在评估研究员的方法中,文献计量学(Bibliometrics,常用的指标包括:引用量、影响因子、H-index等)用一种非常简单直观的方式在一定程度上表现了研究成果的价值。但是很多研究也指出了这种方法自身存在的不足,例如过分简单化 (Belter, 2015; Bornmann&Daniel, 2008; Zhu et al.,2015; Radicchi et al., 2017; Lane, 2010),以及同一种指标在不同学科的反映差异很大的情况 (Belter, 2015)。
其实以文本为基础的评估方法在学术招聘中也十分通用,包括审阅申请者的简历、个人经历、推荐信以及进行笔试面试考核。毋庸置疑,招聘方可以通过这种方式获得对候选人深入的了解,但它的劣势也很明显,就是十分花时间和精力。另外,很多研究也表明这类方式也经常会导致错误的决策,因为它们十分依赖评估人员的经验和能力 (Chen et al., 2011; Rojas, 2013; Moore, 2012)。

评估候选人非常难,没有一种完美的方案。目前来说一种合理的方式就是招聘委员会全面地审阅所有的申请材料并且充分的讨论。但是在大量的信息中去寻找和定位关键内容本身就花去大量的时间,并且还容易出错。因而,使用可视化作为招聘流程的辅助可能会很有帮助。
我也发现其实在这个场景下有相关的可视化方案 (Latif and Beck, 2018; Filipov et al., 2019),但它们的不足也比较明显:只是某一个程度上的信息展现,没有针对特定场景进行设计,或是没有提供直观简单的方式帮助用户去评估科研成果和职业经历。
03 用户需求调研
User Requirement Analysis
我用了通过设计进行研究(Research through design)的方法,所以一开始我需要去了解真实具体的用户场景和存在的问题。因此我通过访谈的方式对四名有学术招聘经验的,并且来自不同领域的法国科学家进行调研。

学术招聘流程
首先我了解了具体的学术招聘流程。尽管不同机构(我的采访对象来自于巴黎索邦大学,法国国家信息研究院,法国国家科学研究中心)的招聘流程会有细节上的差异,但总的来说都是一致的四个阶段。

在招聘流程中遇到的问题
并且通过他们对经历的描述,我总结了11个在这个场景中用户会遇到的问题,并把它们分为三个类别。一些问题被提及了很多次,例如,难以去评估一个研究成果的实用性,以及难以对不同学科领域的研究人员进行比较。
1/ 审阅申请文档
- 太多的文字需要阅读和搜寻
- 并不是每一份信息都有标准的格式
- 手写的文档难以识别和阅读
2/ 评估学术成就
- 难以评估研究成果的实用性和应用性
- 各学科间对学术成就的评估标准差异大
- 难以公正客观地预测科研潜力
- 自我知识的局限影响了对其它学科的判断
3/ 比较不同候选人
- 需要高认知负担,例如需要通过记忆来比较
- 需要高体力负担,例如不断地翻阅
- 难以对不同学科领域的研究人员进行比较
- 评价容易变得主观
邮件调研
为了从另一个角度去了解科研人员习惯通过什么方式去可视化他们的个人经历和研究成果,我进行了在线调查,发送邮件给所有与Aviz合作过的科学家,向他们询问使用可视化在自己的简历、个人网站或是求职材料的经历。同时我也在网上搜集了有关的设计作品。最终我收集了二十多个案例,并且发现大部分是使用时间轴来表达他们的时间维度发展的信息,例如教育背景,职业发展和科研成果。我认为其中很重要的一个原因就是,时间轴直观清晰,并且提供了丰富的设计空间去阐述各种可能的信息。
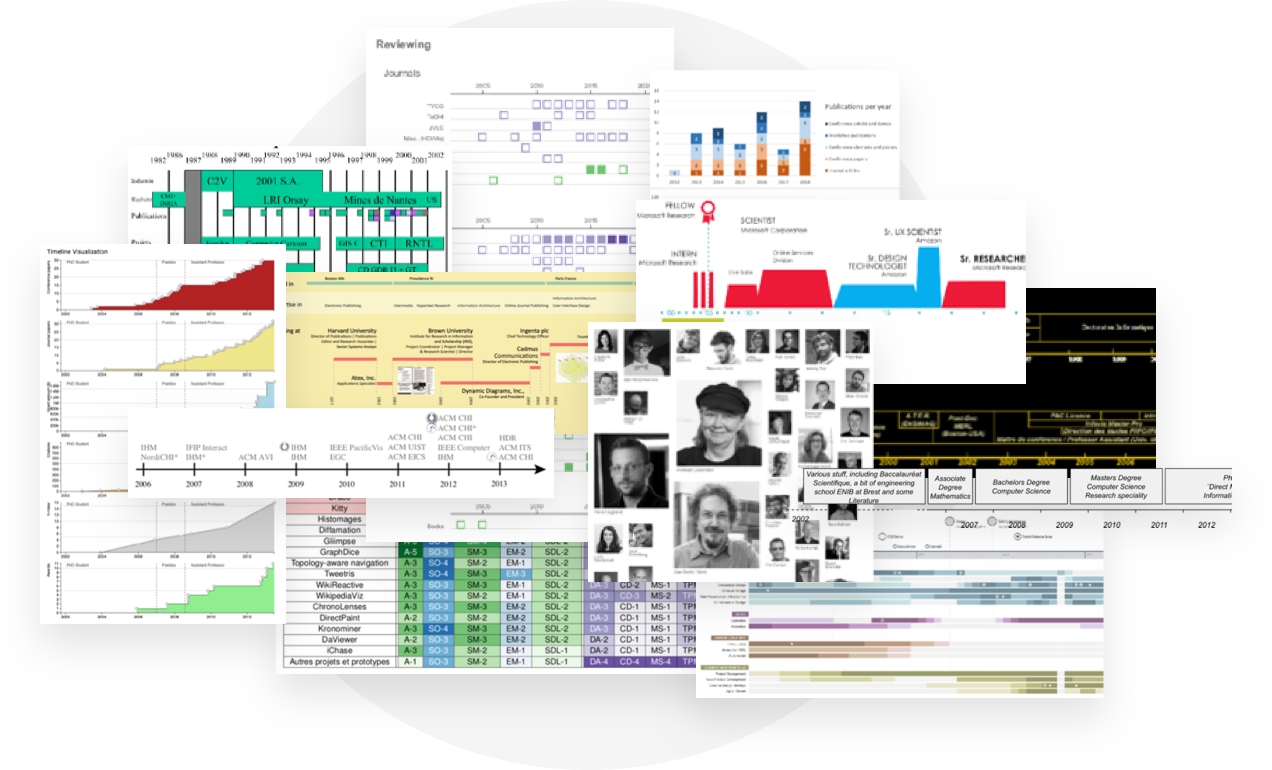

通过用户需求研究,我罗列了一些关键的设计需求点:
提供足够的申请者信息,包括研究成果、教育背景等,能让评估人员可以对申请者有一个粗略但准确的印象
提供可以概览所有申请者的全局视野,能让评估人员在评价时有一个基于平均水平的基准
允许视觉化地比较不同的申请者,能让评估人员快速识别出他们的优劣势
提供直观简单并且是用户习惯的的视觉表达方式,例如时间轴就很好理解
04 可视化设计
Visualization Design
我设计聚焦于招聘年轻研究员的场景,希望提供一个可视化工具去提升对申请者评估的质量,同时提升在招聘流程中的效率和招聘人员对决策的信心
可视化的关键设计资源是数据。我在设计中使用的数据一大部分来自于申请者的简历(包括教育背景、研究经历、发表著作,和其它个人信息)。著作的引用量来自于Google Scholar。论文发表的期刊和会议等级来自于行业内的专家建议,并且参考了CORE Rank提供的数据。

我在五次设计迭代中使用先设计再与可视化专家共同进行启发式走查的方式,输出了数十版设计概念
预备设计
我从一个初期的预设计开始进行迭代测试,这个设计来自于我的导师之一,可视化科学家Petra Isenberg,并且这个设计被真实用于她所参加的一个学术招聘委员会中。
在这个设计中,每一行代表一个申请者(真实匿名数据),时间轴代表了申请者博士和博士后阶段所花费的时间。在后面展示了著作发表在期刊的数量(J)和发表在会议的数量(C)。最后一列展示的是其它评估人员的评分。
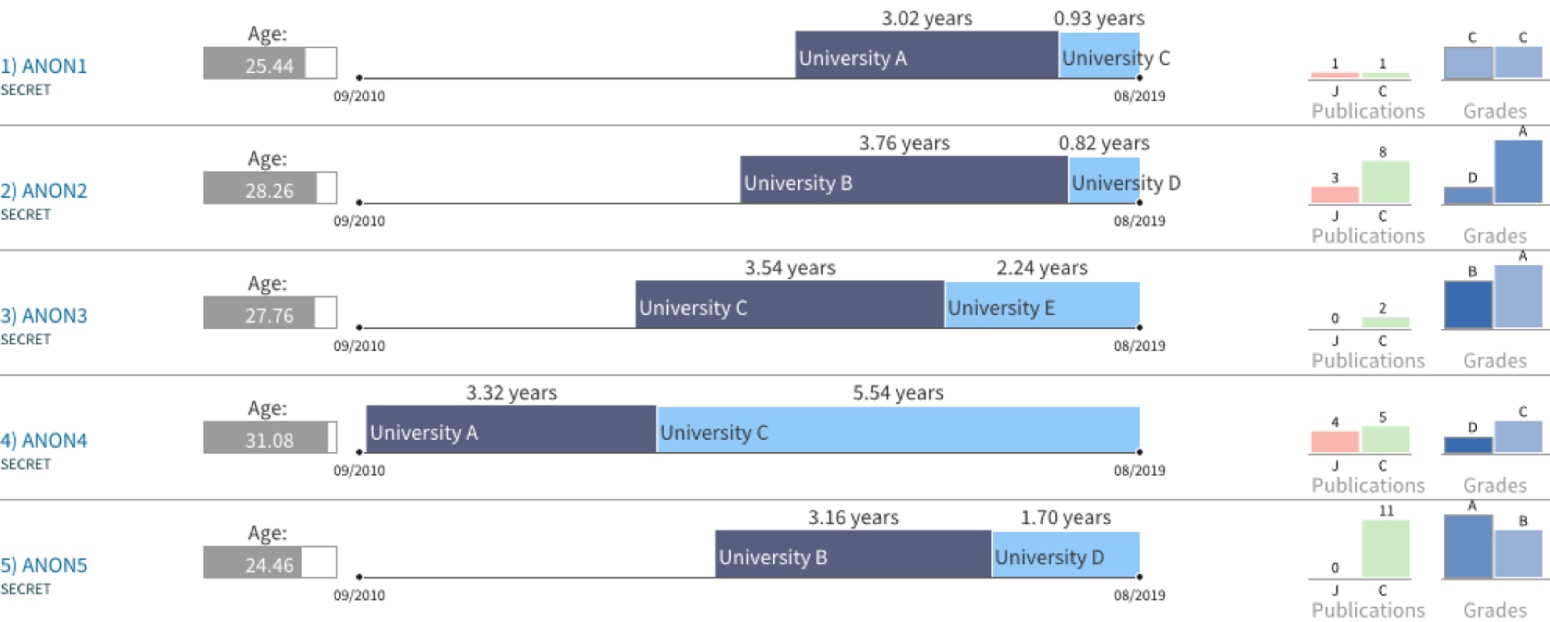
反思
真实用户对于这个设计反馈是非常好的,因为它将很多信息直观化,阅读起来容易多了。但从我设计的角度来说,这个设计仅仅展示了一些定量的统计数据,而忽视了申请者科研成果的质量。
第一次迭代
这个设计只可视化了一位研究员的信息。在左侧是所有申请者的年龄分布(因为年龄其实对筛选很重要),在右侧的时间轴上,我尝试加入了每年发表著作的数量和每年获得的引用量信息在时间轴上。

反思
这个设计尽管多了一些细节,但它依然只表达了综合的科研结果,而并没有说明每个著作的具体细节。
第二次迭代
为了展示更丰富的数据,在这次的迭代中我使用了多个时间轴去展示同一个研究者的多维数据。我是用大面积块状的色彩是因为可以帮助用户在感知层面将信息转化为图形来记忆(Resulting Imagery)。我还增加了每篇著作的引用量展示,用横线分布的方式可以通过线的密度帮助用户更好的识别著作质量的分布情况。

反思
这个设计展示了更丰富的信息,但它的图形表达却占用了非常多的面积。当用户想要对若干个申请者进行比较时,这样大面积的空间消耗会带来很多可读性和可用性的问题。
第三次迭代
这次迭代我使用了可视化科学家Pierre Dragicevic早年的研究成果数据,并做了7种不同的视觉样式变换。这样做是为了加快视觉样式选择的比较和决策。在这个版本中,我使用了非常紧凑的布局,解决了上一个版本的问题。
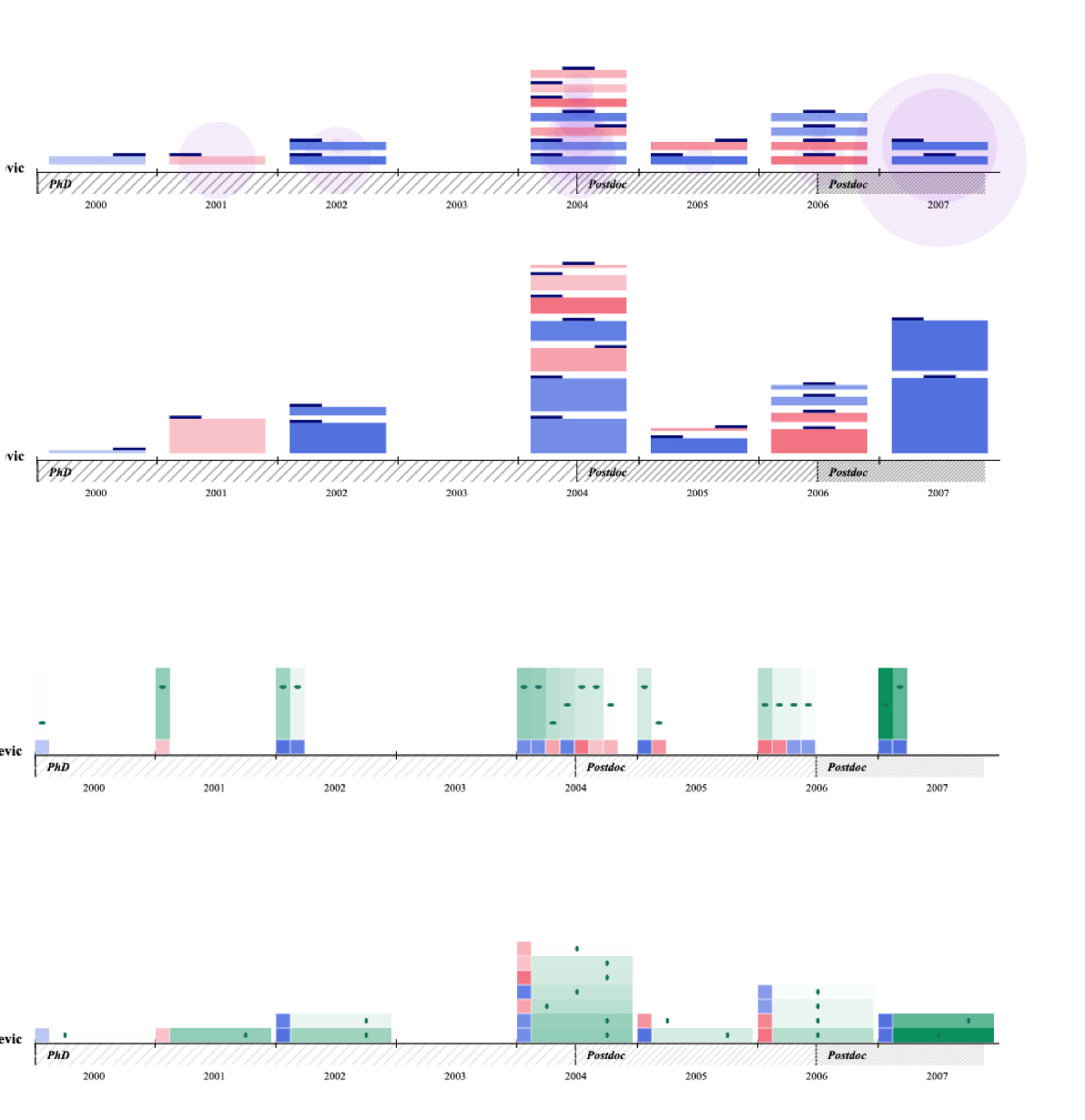
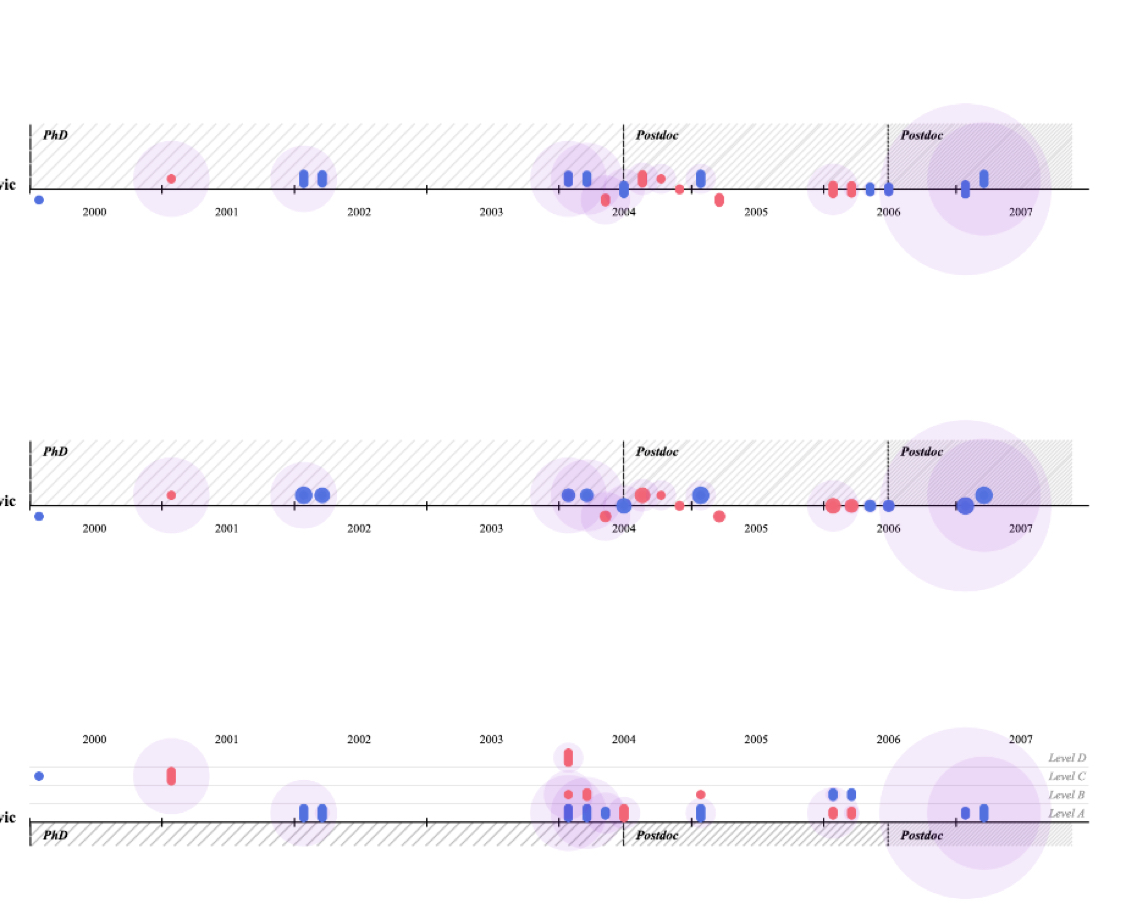
反思
虽然这些设计可以更好的反映科研成果的质量,但在迭代时和不同科学家交流的过程中我发现,对于年轻研究者的评估,学术独立性(Independence)是一个很重要的标准。也就是说,一个研究者如果总是和他的导师一起发表论文,那么他的独立性是远远低于那些有着大范围合作网络的研究者。独立性会影响他日后未来的研究价值。因此,这些差异也应该在设计上被展现。
第四次迭代
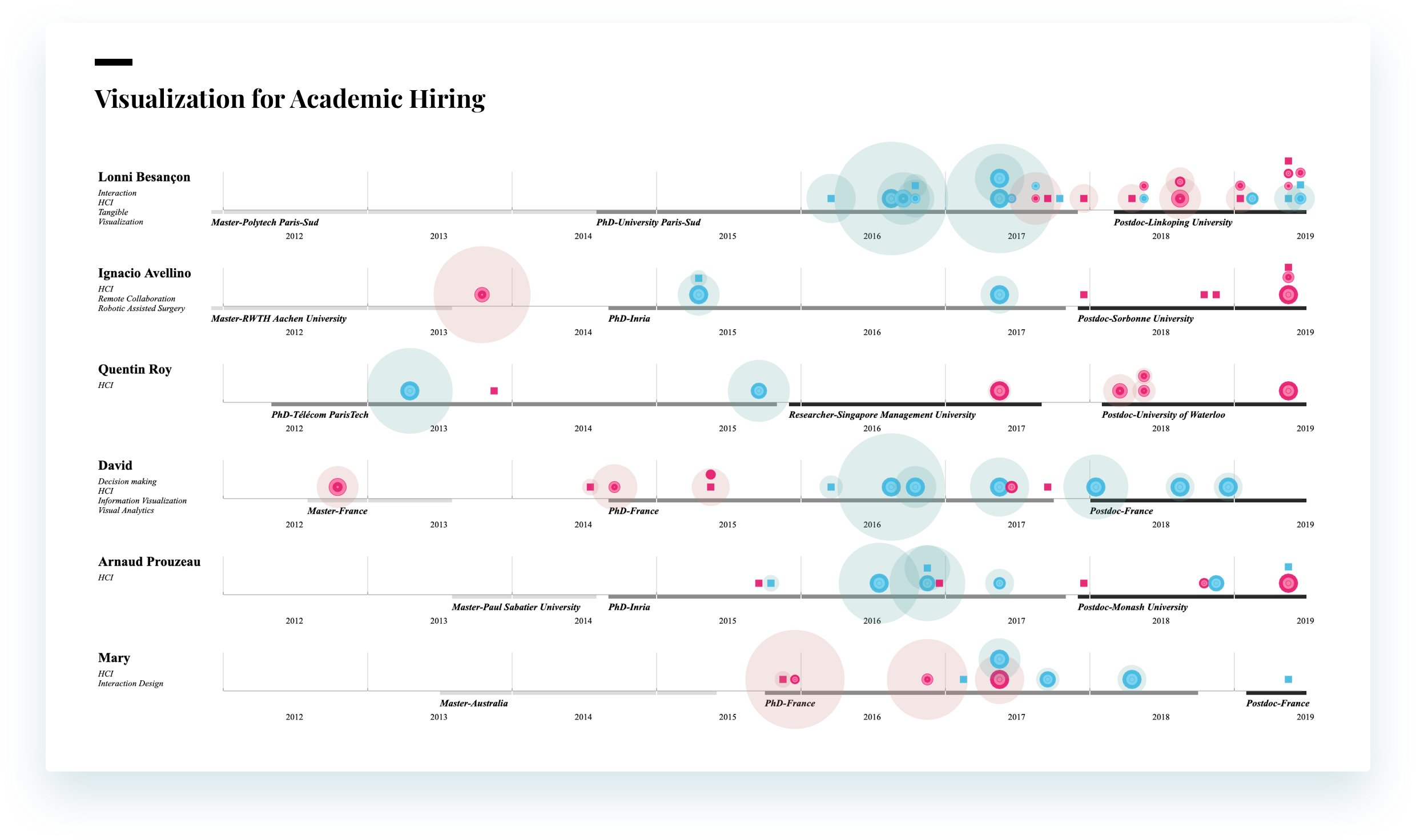
考虑到可视化的可读性、可用性、以及展示效率和美观层面,我们最终选择了第四个设计进行这次迭代改良的基础。在这次迭代中,我使用了六位年轻研究员(28-35岁)的真实数据(有两位研究员匿名是由于我在使用他们的数据时,他们对自己数据使用权限偏好和隐私问题做了限定)。在设计中,每个时间轴都代表他们中的一位。除了基础的视觉编码,我还优化了对于作者顺位的图形化表达。同时我加了一些基础的交互,例如当用户鼠标移动到每篇发表著作上时,会显示它的具体信息。我使用javascript开发了这个可视化设计,使得可以在线使用。点击查看Live Demo




尝试不同的色彩去验证图形设计的视觉识别度。并且将真实数据带入,如下图呈现的这样:

05 设计评估
Evaluation
考虑到时间有限,我在评估过程中只关注两个最重要的维度(1)该可视化的可读性和可用性(2)它在学术招聘中可能产生的影响。并因此设计了两个评估实验。

评估实验 I
首先对那六位提供数据的年轻研究员进行了在线问卷调研,话题围绕着信息准确性和设计的可用性。
选择他们作为研究对象是因为他们有更大的概率发现可视化中存在的问题,因为我用的是他们自己的数据嘛,展示得是好是坏,是否准确,他们的评估是最直观的。然后我根据他们的反馈结果进行设计上的小幅度优化并用于评估实验II。

评估实验 II
在评估实验II中,为了能够观察真实场景中用户的行为和交流,我邀请了三名法国科学家并设立了一个模拟的招聘委员会。
在模拟中,他们将作为招聘委员会的成员,对提供数据的六位年轻研究员进行评估,并给他们最终排录用意向顺序。实验分为两个阶段(第一个阶段为对照组,第二个阶段为实验组),第一个阶段中他们仅使用简历等文本材料进行评估,并给出第一次的排名;而在第二个阶段,他们会使用我的可视化工具去进行第二次的评估和讨论,给出第二次的排名。


设计评估结果
我发现他们在评估过程中使用可视化主要出于四个目的:

用它去验证前一次的排名
某科学家同时看着可视化和排名,说:第一名看起来确实很不错,我们的决策看起来很对,第二名…
通过看可视化来发现一些有趣的信息,然后把这些点带到讨论中
某科学家看着可视化,然后指着其中一个点说:看这里,这个….
用它来辅助自己对于简历上文本信息的理解
某科学家对简历中的一些著作不太理解,然后他在可视化中找到了这些信息去,然后点了点头(?)
用它来作为交流的媒介
某科学家拿着可视化(打印出来的版本),边看着和指着上面的元素对其他人说话。
并且在实验后的调研中,几位科学家都认同使用这个可视化工具进行评估和讨论很有用。他们认为最显著的价值在于有效减短了审阅材料需要耗费的时间。
06 对设计的讨论
Discussion about the design
设计价值
验证了这个设计是有用的后并没有结束。通过整个研究过程,我总结了一些在学术招聘中使用可视化工具可能产生的利害:

它能有效减少审阅候选人资料的时间,同时帮助评估者对申请者的研究背景和成就快速地建立认知基础
观点来自于评估实验II后的采访调研
它能成为某种沟通的媒介,帮助招聘委员会成员聚焦于正在讨论的信息
观点来自于评估实验II中的观察

它可能会让评估者更多的关注定量数据,而减少对于定性数据的重视
观点来自于用户需求研究时的访谈
它能在文本信息的获取和理解上提供帮助
观点来自于评估实验II中的观察
视觉化的排名方式可以帮助招聘委员会更快地反思和讨论
观点来自于评估实验II中的观察
它可能会让评估者对申请者的研究成果发展趋势有误导。比如,在可视化中研究质量看起来是随着时间下降的,是因为新的论文因为时间积累的关系在目前只获得了不多的引用量
观点来自于用户需求研究时的访谈
设计的缺陷和优化空间
在设计中我使用的数据仅仅占评估人员所关心数据的很小一部分,更多的数据需要在未来被纳入设计中。交互设计层面,例如可以自由地给时间轴进行排序,或者以不同的方式对齐时间轴,在这个场景中都等很好的帮助评估人员做比较,这些交互需要在未来被实现出来。
在评估设计做的测试中,也存在很多问题:评估实验的科学家大多数来自人机交互领域,模拟的招聘委员会和真实情况差距比较大;在评估实验II中,我在对照组和实验组中使用了相同的实验对象,这样的设置会大幅度影响结果(尽管参与者尽力保持客观)。未来需要邀请更多来自不同领域的科学家以更好的进行实验模拟;这个阶段的研究仅仅探索了可视化在学术招聘中会产生的影响,未来需要更多的研究和设计工作去验证最初的研究目标,即了解可视化是否能真正提高学术招聘的质量和用户体验。
最后 · 相关链接

鸣谢
真的非常感谢我的两位世界顶级可视化科学家Pierre Dragicevic和Petra Isenberg给我的帮助。当我遇到困惑时他们总是给我非常有价值的指点,让我得以朝着正确的方向继续进行我的研究。感恩!